What is synchronous replication?
Learn about synchronous replication, a method that ensures identical data across sites, essential for financial and healthcare applications demanding high data integrity.

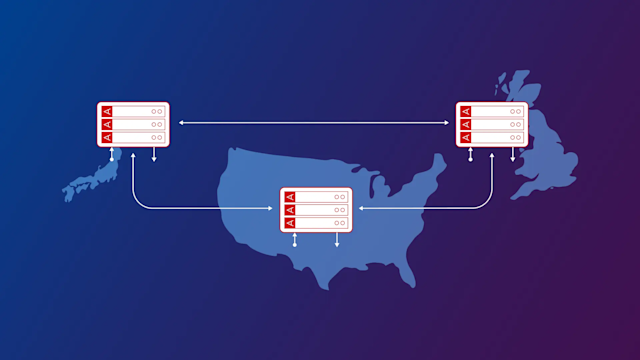
Synchronous replication means that data is written to a primary storage device and a secondary device simultaneously. This method prioritizes data consistency and integrity because both storage locations have the same data at any given moment. Synchronous replication is important in environments where zero data loss is critical, such as financial institutions and healthcare organizations. By maintaining concurrent data copies, this technique reduces the risk of data loss during system failures or disasters.
A fundamental aspect of synchronous replication is its reliance on a high-speed network connection for real-time data transfer between the primary and secondary sites. This requirement can lead to increased infrastructure costs and network latency, which may affect overall system performance. Despite these challenges, synchronous replication is preferable for applications demanding high availability and a zero recovery point objective (RPO).
However, you can’t violate the laws of physics. Because of the speed of light, synchronous replication generally means that the primary and secondary sites typically need to be in the same geographic region. Organizations must assess their infrastructure and network capabilities to determine whether the benefits of synchronous replication are worth the cost. Additionally, the increased demand for bandwidth may require more networking infrastructure to support the real-time data mirroring process.
For situations that need immediate data consistency and recovery, synchronous replication is a good option. IT professionals and disaster recovery specialists need to evaluate their needs and infrastructure capabilities before implementing synchronous replication to make sure the chosen replication strategy aligns with organizational objectives and regulatory requirements.
What is a replica?
A replica is a duplicate copy of data created and maintained by a replication process. A replica is not merely a backup but typically a "live" or standby copy that’s actively managed and maintained. Replicas make data more available, reduce downtime, and are more resilient because they create a reliable backup across multiple nodes. In replication strategies, whether synchronous, asynchronous, or near-synchronous, the primary goal is to maintain accurate and usable replicas at secondary locations, enabling quick recovery or failover when needed.
Synchronous standby replication
An extension of synchronous replication is synchronous standby, where secondary servers remain synchronized and ready for immediate failover. Synchronous standby replication is a specific instance of synchronous replication, with a focus on one or more standby servers that acknowledge transactions before commit, which provides quick recovery and reduces downtime during primary server failures. This approach is ideal for mission-critical applications demanding continuous availability. However, it requires robust infrastructure, including high-bandwidth, low-latency networks, potentially increasing complexity and costs. If organizations want to do this, they need to make sure their infrastructure is up to the task.
Asynchronous replication
Asynchronous replication is a data synchronization method where updates to a primary node do not immediately reflect in the secondary storage location. This technique means data gets written to the primary site first, followed by a delayed transfer to the secondary site. The advantage of this delay means asynchronous replication can handle long distances between storage locations without as much of a performance hit.
One of the main advantages of asynchronous replication is its ability to support high-latency networks, making it suitable for geographically dispersed data centers. Businesses get a backup dataset without requiring constant real-time connectivity. This method is also generally more bandwidth-efficient than synchronous replication, as it can batch updates before sending them to the secondary site.
However, this efficiency comes with a trade-off. If a failure occurs between the primary and secondary site during the delay period, some of the most recent data changes might not be captured, meaning data could be lost.
Another consideration is the consistency model. Asynchronous replication might lead to temporary inconsistencies between the primary and secondary datasets, which can be a concern for applications requiring strict data consistency. Despite this, many applications where eventual consistency is acceptable find asynchronous replication suitable.
Asynchronous replication typically costs less and uses fewer resources than synchronous replication. It is particularly useful in scenarios where the risk of data loss is manageable and the primary goal is to maintain a backup that can be quickly brought online in case of primary site failure. This technique is widely used in disaster recovery, where IT specialists and storage managers want to make sure there’s a copy of data while also keeping costs low.
Discover how Aerospike's Cross Datacenter Replication (XDR) enhances global data performance with low latency and precise control.
Near-synchronous replication
Near-synchronous replication offers a middle ground between synchronous and asynchronous replication methods. This approach has lower latency compared with asynchronous replication while avoiding the performance hit associated with synchronous replication. It does this by implementing a predetermined delay in the replication process, so data is transmitted with minimal lag while maintaining system performance.
Unlike synchronous replication, which waits for confirmation from the target site before proceeding, near-synchronous replication sends data to the secondary site with a slight delay. This delay, unlike the often longer lag in asynchronous replication, means the data remains up-to-date but doesn’t affect the primary system's performance as much. This makes near-synchronous replication a better choice for businesses seeking to balance data integrity and system efficiency.
One of the biggest advantages of near-synchronous replication is that it provides almost real-time data protection without the performance requirements of full synchronous replication. Businesses get data consistency across multiple sites, which is important for applications that demand high availability and reliability.
However, near-synchronous replication may not be suitable for all scenarios. For example, organizations that change their data often, or with applications that require immediate confirmation of data write integrity, may prefer synchronous replication.
In summary, near-synchronous replication serves as a practical alternative for IT professionals and disaster recovery specialists looking for a happy data protection medium. By understanding the nuances of near-synchronous replication, IT teams can decide which system best meets their organization's performance and reliability needs.
Synchronous replication vs. asynchronous replication
When choosing between synchronous and asynchronous replication, organizations must evaluate their requirements for data integrity, performance, geographic distribution, and cost.
| Attribute | Synchronous replication | Asynchronous replication | Near-synchronous replication |
|---|---|---|---|
| Data integrity | Provides transactional consistency; minimal risk of data loss | Potential for data loss due to delayed replication | Sends data with a slight delay, which reduces both data loss and latency |
| Performance impact | Immediate acknowledgment required; potential latency | Reduced latency; updates are batched and delayed | Reduces performance impact by introducing delay |
| Network requirements | Requires reliable, consistently low-latency network infrastructure | Flexible; works across long distances and higher latency | Provides almost real-time data protection without the performance requirements of full synchronous replication |
| Cost and complexity | Higher cost and complexity; specialized infrastructure needed | Lower cost and complexity; more flexible infrastructure choices | Lower cost and complexity; more flexible infrastructure choices |
| Recovery objectives (RPO/RTO) | Zero/near-zero RPO and shorter RTO; immediate replica availability | Non-zero RPO; acceptable RTO if managed properly | Non-zero RPO; lower RTO than asynchronous |
| Use cases | Multi-regional strong consistency, including between continents (e.g., global banking, finance, and inventory management) | Applications that need instantaneous reads and fast local writes (AdTech, fraud detection, recommendation engines, and more) | High-throughput applications that need fast recovery and can tolerate minimal lag (e.g., mobile gaming state sync, real-time personalization, low-latency cross-region failover) |
Data integrity
In terms of data integrity and the risk of data loss, synchronous replication provides transactional consistency because every transaction committed on the primary node is simultaneously replicated to the secondary replica. This method virtually eliminates the risk of data loss, making it especially valuable in highly regulated sectors such as finance and healthcare, where transactional accuracy is important.
Conversely, asynchronous replication involves delayed transfer of transactions to secondary replicas, which can lead to potential discrepancies during system failures. Transactions completed shortly before an outage might fail to replicate, thereby introducing the possibility of data loss.
However, because synchronous replication requires immediate acknowledgment from replicas, it can introduce noticeable latency, particularly in high-performance applications, especially if network conditions deteriorate. On the other hand, asynchronous replication reduces the performance hit by batching updates and sending them later, making it more suitable for scenarios where performance and responsiveness are more important than immediate data consistency.
Infrastructure requirements
Network and infrastructure requirements also vary between the two approaches. Synchronous replication needs a robust, high-speed, low-latency network infrastructure, which typically limits deployment distances and can be more complex and expensive. In contrast, asynchronous replication allows greater flexibility, handling replication across geographically dispersed data centers even under higher latency conditions or less network bandwidth.
Cost and complexity considerations are other factors. Synchronous replication generally involves higher infrastructure and operational costs because it requires specialized networking equipment, storage solutions that can keep up with the demands of synchronous replication, and more hands-on management. Asynchronous replication tends to be more cost-effective, providing organizations with greater flexibility regarding infrastructure choices and typically reducing the need for advanced, costly networking components.
Recovery objectives
Recovery objectives, including RPO and recovery time objectives (RTO), are also part of the decision. Synchronous replication has near-zero RPO, reducing the risk of transaction loss, and often provides shorter RTOs because up-to-date replicas are already available. Asynchronous replication inherently means RPO can’t be zero because it uses delayed batching, yet can still deliver acceptable RTOs if carefully managed, balancing risk tolerance against operational efficiency.
Ultimately, which one is better for your organization depends on your needs and priorities. Organizations should adopt synchronous replication when they require data consistency and integrity, despite the potential increase in complexity and costs. Conversely, asynchronous replication is better suited for environments where some degree of data loss risk is acceptable and performance is emphasized, especially when managing geographically dispersed data centers or budget-conscious disaster recovery strategies.
Put Aerospike’s active-active synchronous replication to work
Now that you’ve compared synchronous, asynchronous, and near-synchronous strategies, it’s time to see how they look in a real-time production database. Aerospike delivers sub-millisecond performance and five-nines availability by combining fully synchronous, strongly consistent replication inside each cluster with ultra-efficient active-active, synchronous clustering for global disaster recovery and active-active workloads.
Move from theory to practice
Try it out. Launch a free multi-node Aerospike Enterprise trial (Docker or Kubernetes) and watch strong consistency in action, with no credit card required.
Research it. Download the white paper "Achieving resiliency with Aerospike’s real-time data platform" to learn how customers in finance, telco, and AdTech get zero-loss RPOs without sacrificing speed.
Design session with experts. Book a live architecture review and map Aerospike replication modes to your RTO/RPO and geo-distribution targets.
Ready to turn replication theory into real-world resiliency? See how Aerospike lets you build applications that never lose data, even at petabyte scale.